Interactive Machine Comprehension with Information Seeking Agents
Aug 27, 2019·
,
,
,
,
,
·
0 min read
Xingdi Yuan
Jie Fu
Marc-Alexandre Cote
Yi Tay
Chris Pal
Adam Trischler
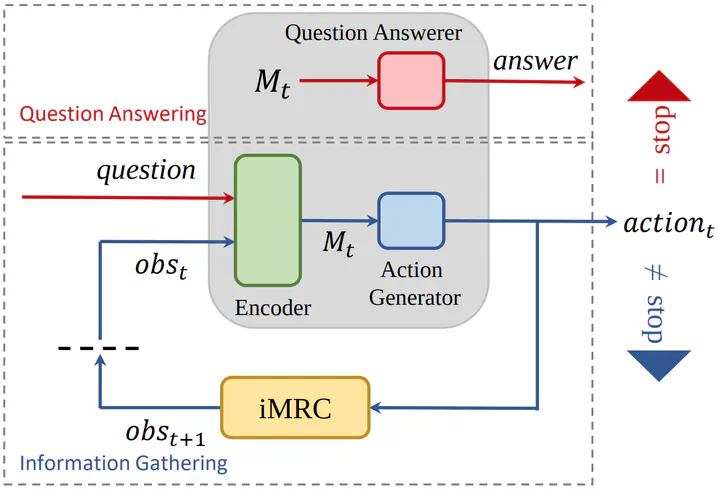
Abstract
Existing machine reading comprehension (MRC) models do not scale effectively to real-world applications like web-level information retrieval and question answering (QA). We argue that this stems from the nature of MRC datasets most of these are static environments wherein the supporting documents and all necessary information are fully observed. In this paper, we propose a simple method that reframes existing MRC datasets as interactive, partially observable environments. Specifically, we “occlude” the majority of a document’s text and add context-sensitive commands that reveal “glimpses” of the hidden text to a model. We repurpose SQuAD and NewsQA as an initial case study, and then show how the interactive corpora can be used to train a model that seeks relevant information through sequential decision making. We believe that this setting can contribute in scaling models to web-level QA scenarios.
Type
Publication
In ACL