Massive Editing for Large Language Models via Meta Learning
Abstract
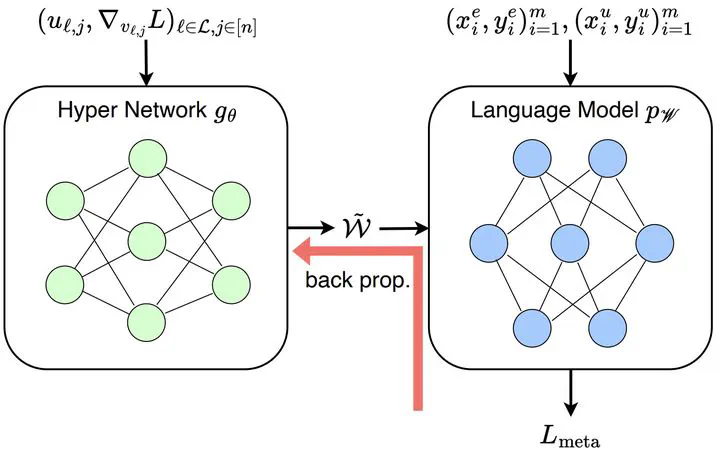
While large language models (LLMs) have enabled learning knowledge from the pre-training corpora, the acquired knowledge may be fundamentally incorrect or outdated over time, which necessitates rectifying the knowledge of the language model (LM) after the training. A promising approach involves employing a hyper-network to generate parameter shift, whereas existing hyper-networks suffer from inferior scalability in synchronous editing operation amount. To mitigate the problem, we propose the MAssive Language Model Editing Network (MALMEN), which formulates the parameter shift aggregation as the least square problem, subsequently updating the LM parameters using the normal equation. To accommodate editing multiple facts simultaneously with limited memory budgets, we separate the computation on the hyper-network and LM, enabling arbitrary batch size on both neural networks. Our method is evaluated by editing up to thousands of facts on LMs with different architectures, i.e., BERT-base, GPT-2, T5-XL (2.8B), and GPT-J (6B), across various knowledge-intensive NLP tasks, i.e., closed book fact-checking and question answering. Remarkably, MALMEN is capable of editing hundreds of times more facts than strong baselines with the identical hyper-network architecture and outperforms editor specifically designed for GPT. Our code is available at https://github.com/ChenmienTan/malmen.
Publication
In ICLR