Stacking Your Transformers: A Closer Look at Model Growth for Efficient LLM Pre-Training
May 30, 2024·
,
,
,
,
,
,
,
·
0 min read
Wenyu Du
Tongxu Luo
Zihan Qiu
Zeyu Huang
Yikang Shen
Reynold Cheng
Yike Guo
Jie Fu
Abstract
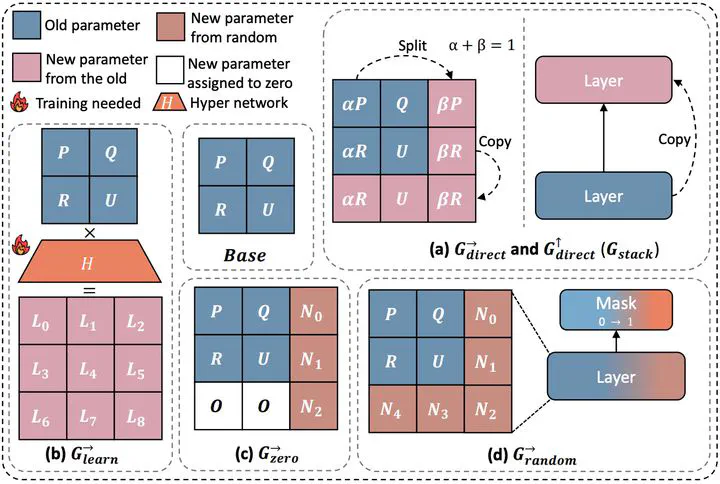
LLMs are computationally expensive to pre-train due to their large scale. Model growth emerges as a promising approach by leveraging smaller models to accelerate the training of larger ones. However, the viability of these model growth methods in efficient LLM pre-training remains underexplored. This work identifies three critical obstacles. (O1) lack of comprehensive evaluation, (O2) untested viability for scaling, and (O3) lack of empirical guidelines. To tackle O1, we summarize existing approaches into four atomic growth operators and systematically evaluate them in a standardized LLM pre-training setting. Our findings reveal that a depthwise stacking operator, called Gstack, exhibits remarkable acceleration in training, leading to decreased loss and improved overall performance on eight standard NLP benchmarks compared to strong baselines. Motivated by these promising results, we conduct extensive experiments to delve deeper into Gstack to address O2 and O3. For O2 (untested scalability), our study shows that Gstack is scalable and consistently performs well, with experiments up to 7B LLMs after growth and pre-training LLMs with 750B tokens. For example, compared to a conventionally trained 7B model using 300B tokens, our Gstack model converges to the same loss with 194B tokens, resulting in a 54.6% speedup. We further address O3 (lack of empirical guidelines) by formalizing guidelines to determine growth timing and growth factor for Gstack, making it practical in general LLM pre-training. We also provide in-depth discussions and comprehensive ablation studies of Gstack. Our code and pre-trained model are available at https://llm-stacking.github.io/.