Beyond Fully-Connected Layers with Quaternions: Parameterization of Hypercomplex Multiplications with 1/n Parameters
Apr 2, 2021·
,
,
,
,
,
,
·
1 min read
Aston Zhang
Yi Tay
Shuai Zhang
Alvin Chan
Anh Tuan Luu
Siu Cheung Hui
Jie Fu
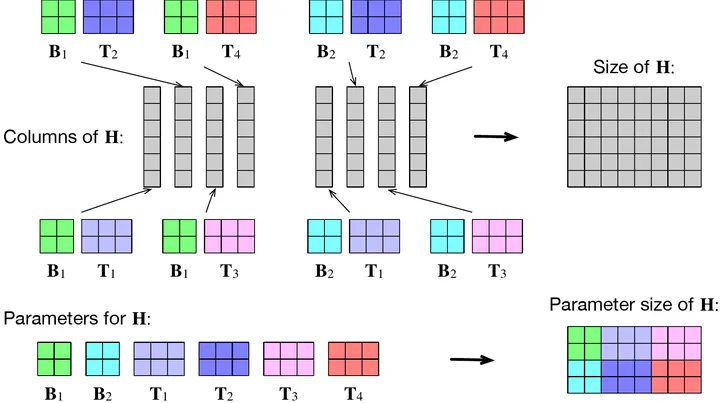
Abstract
Recent works have demonstrated reasonable success of representation learning in hypercomplex space. Specifically, “fully-connected layers with Quaternions” (4D hypercomplex numbers), which replace real-valued matrix multiplications in fully-connected layers with Hamilton products of Quaternions, both enjoy parameter savings with only 1/4 learnable parameters and achieve comparable performance in various applications. However, one key caveat is that hypercomplex space only exists at very few predefined dimensions (4D, 8D, and 16D). This restricts the flexibility of models that leverage hypercomplex multiplications. To this end, we propose parameterizing hypercomplex multiplications, allowing models to learn multiplication rules from data regardless of whether such rules are predefined. As a result, our method not only subsumes the Hamilton product, but also learns to operate on any arbitrary nD hypercomplex space, providing more architectural flexibility using arbitrarily $1/n$ learnable parameters compared with the fully-connected layer counterpart. Experiments of applications to the LSTM and Transformer models on natural language inference, machine translation, text style transfer, and subject verb agreement demonstrate architectural flexibility and effectiveness of the proposed approach.
Publication
In ICLR
Our paper received the Outstanding Paper Award (8 out of 860 accepted papers).