Abstract
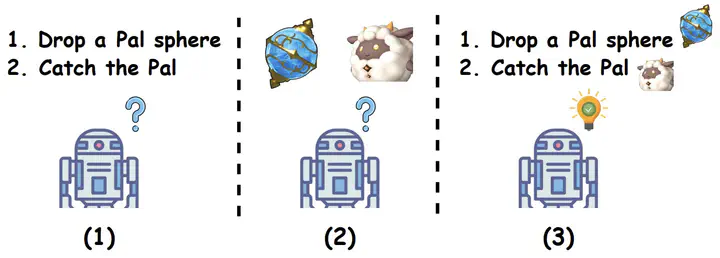
Developing a generalist agent is a longstanding objective in artificial intelligence. Previous efforts utilizing extensive offline datasets from various tasks demonstrate remarkable performance in multitasking scenarios within Reinforcement Learning. However, these works encounter challenges in extending their capabilities to new tasks. Recent approaches integrate textual guidance or visual trajectory into decision networks to provide task-specific contextual cues, representing a promising direction. However, it is observed that relying solely on textual guidance or visual trajectory is insufficient for accurately conveying the contextual information of tasks. This paper explores enhanced forms of task guidance for agents, enabling them to comprehend gameplay instructions, thereby facilitating a “read-to-play” capability. Drawing inspiration from the success of multimodal instruction tuning in visual tasks, we treat the visual-based RL task as a long-horizon vision task and construct a set of multimodal game instructions to incorporate instruction tuning into a decision transformer. Experimental results demonstrate that incorporating multimodal game instructions significantly enhances the decision transformer’s multitasking and generalization capabilities.