DrMAD: Distilling Reverse-Mode Automatic Differentiation for Optimizing Hyperparameters of Deep Neural Networks
Abstract
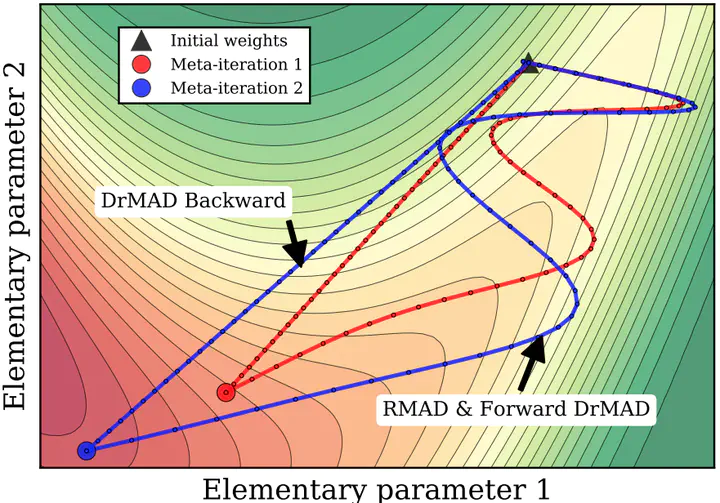
The performance of deep neural networks is well-known to be sensitive to the setting of their hyperparameters. Recent advances in reverse-mode automatic differentiation allow for optimizing hyperparameters with gradients. The standard way of computing these gradients involves a forward and backward pass of computations. However, the backward pass usually needs to consume unaffordable memory to store all the intermediate variables to exactly reverse the forward training procedure. In this work we propose a simple but effective method, DrMAD, to distill the knowledge of the forward pass into a shortcut path, through which we approximately reverse the training trajectory. Experiments on several image benchmark datasets show that DrMAD is at least 45 times faster and consumes 100 times less memory compared to state-of-the-art methods for optimizing hyperparameters with minimal compromise to its effectiveness. To the best of our knowledge, DrMAD is the first research attempt to make it practical to automatically tune thousands of hyperparameters of deep neural networks.