LLMs, Part 2
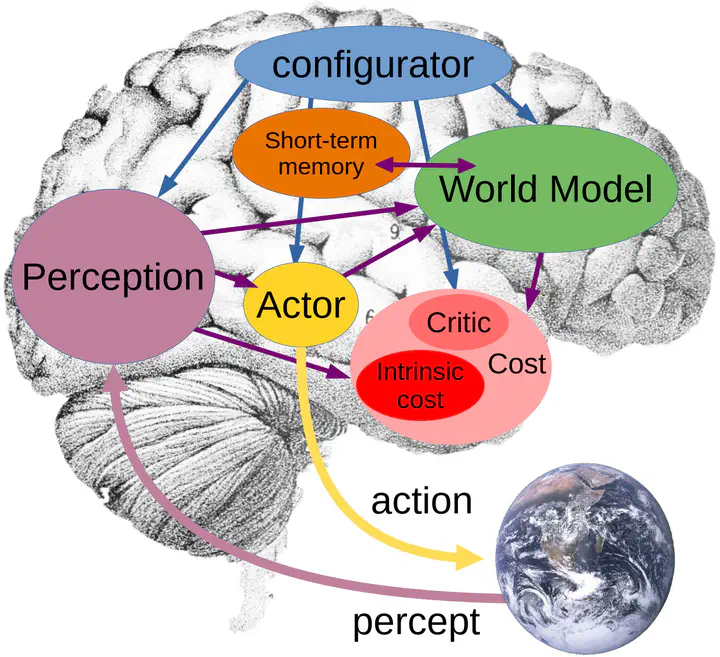 Taken from “A Path Towards Autonomous Machine Intelligence”, by Yann LeCun
Taken from “A Path Towards Autonomous Machine Intelligence”, by Yann LeCun
Introduction
Following the formulation in Distilling System 2 into System 1, given an input $x$, System-1 produces the output $y$ directly: $S_{\mathrm{I}}(x)=f_{\theta}(x)\to y$. In contrast, System-2, takes an LLM $f_{\theta}$ and input $x$ and generates intermedaite tokens $z$: $S_\text{II}{(x;f_\theta)}\to z,y$, which can be seen as a form of meta learning. I plan to design scalable System-2 LLMs from the meta learning perspective.
My Related Works
Neural Architectures
- Unlocking Emergent Modularity in Large Language Models, NAACL 2024 Outstanding Paper
- HyperMoE: Towards Better Mixture of Experts via Transferring Among Experts, ACL 2024
- Prototype-based HyperAdapter for Sample-Efficient Multi-task Tuning, EMNLP 2023
- Beyond Fully-Connected Layers with Quaternions: Parameterization of Hypercomplex Multiplications with $1/n$ Parameters, ICLR 2021 Outstanding Paper
Multi-Modal & Reinforcement Learning
- Think Before You Act: Decision Transformers with Internal Working Memory, ICML 2024
- MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training, ICLR 2024
- Interactive Natural Language Processing, arXiv 2023
Human-AI Alignment
- AI Alignment: A Comprehensive Survey, arXiv 2023
- Would you Rather? A New Benchmark for Learning Machine Alignment with Cultural Values and Social Preferences, ACL 2020
Meta Learning
Jie Fu
Research Scientist
Focus on Deep Learning, System-2 Language Models, Reinforement Learning, Agent, AI Safety.